0
Creating Indexes
Posted by Danielle Smith
on
15:07
in
Indexes
Good afternoon everyone! Today I will be discussing Indexes, what they are, why they are useful and how they can be implemented within your database. I have used Indexes quite a lot in the working environment, especially on larger projects where vast amounts of data need to be brought back to the user.
Generally, Clustered Indexes are quicker to read from, but they are slower to write to as the data in the table may need to be rearranged to fit accordingly. Clustered Indexes are usually used on ID columns.
Non-Clustered Indexes are slower than clustered indexes at reading, however you can have as many Non-Clustered Indexes as you like, plus there is no need to reorder the data if more data is added. Non-Clustered Indexes are usually used on non-ID columns, typically on columns specified in WHERE and ORDER BY clauses.
User Interface:
In order to view the Indexes that already exist on a table, click on your Table Name > Indexes. As you can see from the example below, there are already 2 Indexes in existence. It's usually a good idea to name your indexes appropriately in order to make it easier to distinguish. As a rule, I declare my indexes using the following convention: "Ix_TableName_ColumnName".

To add a new Index, right-click the Indexes folder and click on New Index > Non-Clustered Index... (as you can see from this example, because we already have a Clustered Index on this table, the option to add another one has been greyed out):





SQL Code:

User Interface:
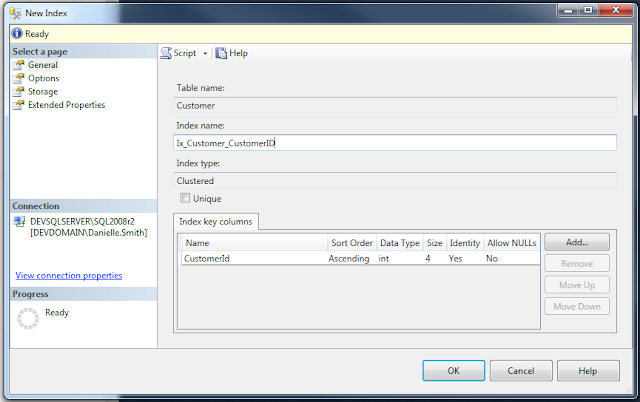
As mentioned previously, in order to view the Indexes that already exist on a table, click on your Table Name > Indexes. As you can see, in this example there are no indexes at all. This is because in this example, I am creating the first index on the table; a clustered index on an ID column.

Right-click the Indexes folder and click on New Index > Clustered Index...:






What is an Index?
Indexes are a type of data structure which is used to increase the performance and speed of retrieving data from a data table. There are 2 different index architectures in SQL Server; Clustered and Non-Clustered.Clustered Index
A Clustered Index stores database table rows physically on the disk in the same order as the index. However, because of this, there can only ever be one Clustered Index on a specific table.Non-Clustered Index
A Non-Clustered Index contains a list of pointers to the original row. So when the query is called, the pointers point to the correct rows in the database. You can have as many Non-Clustered Indexes on a table as you like.The UNIQUE Constraint
Both types of Index architecture can be declared as UNIQUE. This means that they have a unique constraint placed on them, so that each value occurs only exactly once. Note that there is no such thing as a UNIQUE Index as an additional architecture! Clustered and Non-Clustered Indexes can both have the UNIQUE constraint applied to it (so they become UNIQUE Clustered Index and UNIQUE Non_Clustered Index but you will never have just a UNIQUE Index).Types of Index
There are also 4 different "types" of Index:Dense
A file with pairs of keys and pointers for every data row in a data file. Every key references a pointer that points to a particular data row in the sorted data file.Sparse
A file with pairs of keys and pointers for every block (or sequence of bytes) in a data file. Every key references a pointer that points to a particular block in the sorted data file.Bitmap
The majority of the data within the data file is stored within bit arrays (bitmaps) and performs bitwise logical operators on these bitmaps in order to point to the correct data rows.Reverse
A reverse key reverses the key value before it is entered into the index.Why Are They Useful?
Indexes are used as a way of making your queries run faster.Generally, Clustered Indexes are quicker to read from, but they are slower to write to as the data in the table may need to be rearranged to fit accordingly. Clustered Indexes are usually used on ID columns.
Non-Clustered Indexes are slower than clustered indexes at reading, however you can have as many Non-Clustered Indexes as you like, plus there is no need to reorder the data if more data is added. Non-Clustered Indexes are usually used on non-ID columns, typically on columns specified in WHERE and ORDER BY clauses.
How Can They Be Implemented In My System?
The below examples show Indexes being added to a database system. You can add Indexes both via the User Interface and via SQL statements:Non-Clustered Index
User Interface:
In order to view the Indexes that already exist on a table, click on your Table Name > Indexes. As you can see from the example below, there are already 2 Indexes in existence. It's usually a good idea to name your indexes appropriately in order to make it easier to distinguish. As a rule, I declare my indexes using the following convention: "Ix_TableName_ColumnName".
- What they actually are (Ix_ is an Index, Sp_ is a Stored Procedure, Fn_ is a Function etc.).
- What table the Index is found on.
- What column the Index is on.
To add a new Index, right-click the Indexes folder and click on New Index > Non-Clustered Index... (as you can see from this example, because we already have a Clustered Index on this table, the option to add another one has been greyed out):
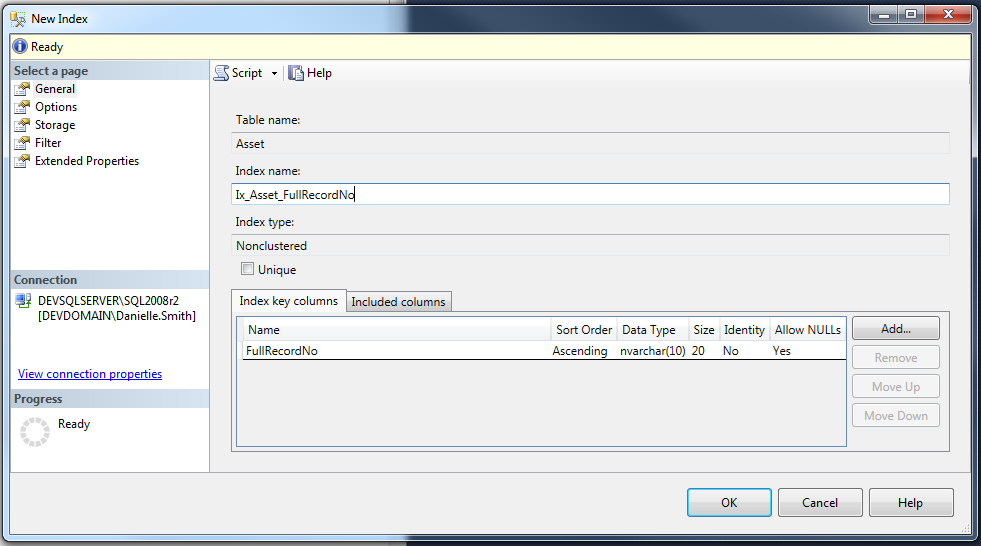
Next, you have to add the Index Key Columns by clicking on Add:

...and then select the table column(s) you wish to place the Index on from the multi-select list:
Now you should see your added Index columns in the table at the bottom of the screen (see visual below). You can add multiple and you can also add Included columns as well. If you want to make your Index UNIQUE, make sure that the Unique check box has been ticked. Once you're happy with your Index (and don't forget to give it an appropriate name!), click OK:
After refreshing the Indexes folder, you can now see that the new Index has been added with the others in the list:
SQL Code:
The snippet of SQL code below will produce exactly the same result as above (it's totally up to personal preference which method you wish to undertake but it's valuable to know both):
Clustered Index
User Interface:
As mentioned previously, in order to view the Indexes that already exist on a table, click on your Table Name > Indexes. As you can see, in this example there are no indexes at all. This is because in this example, I am creating the first index on the table; a clustered index on an ID column.
Right-click the Indexes folder and click on New Index > Clustered Index...:
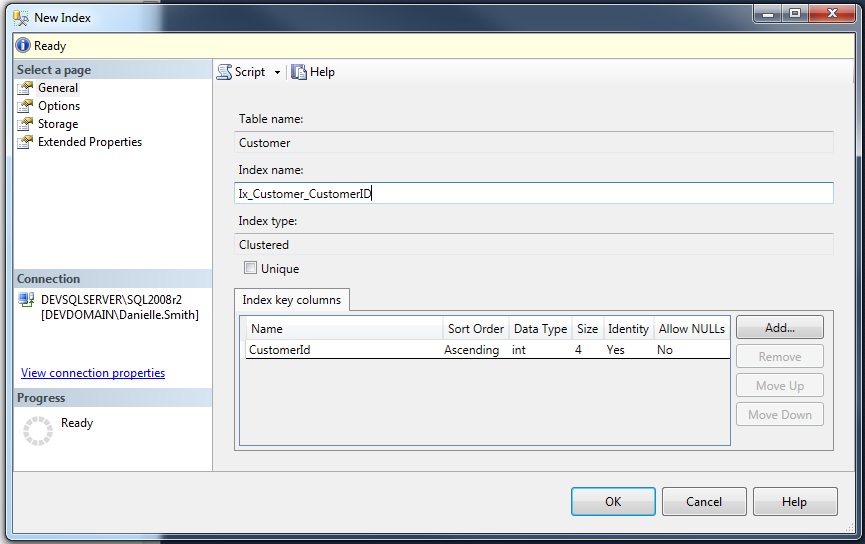
Next, you have to add the Index Key Columns by clicking on Add:

...and then select the table column(s) you wish to place the Index on from the multi-select list:
Now you should see your added Index columns in the table at the bottom of the screen (see visual below). You can add multiple and you can also add Included columns as well. If you want to make your Index UNIQUE, make sure that the Unique check box has been ticked. Once you're happy with your Index (and don't forget to give it an appropriate name!), click OK:
After refreshing the Indexes folder, you can now see that the new Index has been added to the list:
SQL Code:
The snippet of SQL code below will produce exactly the same result as above (it's totally up to personal preference which method you wish to undertake but it's valuable to know both):
What Next...
Tomorrow, I will be looking at creating Indexes on Views as they can greatly improve the speed in which you return your data to your users.
As A Final Word...
Thank you for reading today's blog post! If you have any questions/comments/feedback, please leave them in the comments section below and I will get back to you as soon as I can. Alternatively, please like my SQL Genius Facebook Page and leave a message on there.

Post a Comment
Please post any feedback or comments here...